
An agentic coding model is an AI system that plans a task, uses tools, drives a terminal or browser, edits a real codebase across many steps, and checks and corrects its own work until the goal is reached. A chatbot answers a single prompt and then waits. An autocomplete finishes the line you are typing. The agentic model is the only one of the three you can hand a goal to — "make this failing test suite pass" — and it will pursue that goal end to end.
This distinction is the foundation of everything else on ThePlanetTools.ai. Once you understand it, the difference between a $20-per-month chat window and a model that can refactor an entire service on its own stops being marketing language and becomes a concrete, testable capability. Below we define the term precisely, break down the three modes of AI-assisted coding, explain what actually makes a model "agentic," and map the 2026 landscape of both closed and open-weight models built for this kind of work.
What Is an Agentic Coding Model?
An agentic coding model is a large language model wrapped in a loop that lets it take actions in the real world, observe the results, and decide what to do next — repeatedly, without a human in the loop for every step. Instead of producing text and stopping, it operates a computer: it reads files, runs shell commands, executes tests, searches documentation, and edits code. The word "agentic" refers to agency — the model behaves like an autonomous agent that owns a goal, not a passive tool that answers a question.
The clearest way to understand it is to compare it against the two things people already know: autocomplete and chat.
Autocomplete vs Chatbot vs Agent: The Three Modes
| Mode | What you give it | What it does | Time horizon |
|---|---|---|---|
| Autocomplete | Your cursor position | Predicts the next line or block of code | Milliseconds — one suggestion |
| Chatbot | A single prompt | Returns one answer, then stops and waits | One turn — one response |
| Agentic model | A goal or task | Plans, runs tools, edits files, runs tests, self-corrects across many steps | Minutes to hours — a whole task |
All three can be powered by the same underlying model. What changes is the scaffolding around it and the permissions it is given. GitHub Copilot's inline suggestions are autocomplete. A plain chat window is a chatbot. Give that same model a terminal, file-system access, and a loop that feeds tool results back in, and it becomes an agent. This is why a single model such as Claude Sonnet 5 can appear as a chat assistant in one product and as an autonomous coding agent in another — the model is the engine, the agentic harness is what turns the engine into a vehicle.

What Actually Makes a Model "Agentic"
"Agentic" is not a marketing badge you can stick on any model. It is a set of concrete capabilities. A model earns the label when it can reliably do the following five things.
1. Tool use
The single most important ingredient. An agentic model can call tools — a shell, a file editor, a code interpreter, a web search, a test runner — and read their output. Modern models are trained to emit structured tool calls and then continue reasoning based on what comes back. Open standards such as the Model Context Protocol (MCP) have made tool use portable across products, which is a big part of why 2026 agents feel so capable. If a model cannot use tools, it cannot be agentic; it can only describe what a tool would do. We cover this shift in depth in our piece on the agentic web.
2. Multi-step, long-horizon execution
A chatbot works in single turns. An agent works in trajectories — long chains of action and observation that can run for dozens or hundreds of steps. Fixing a real bug might mean reproducing it, reading five files to understand the call graph, editing three of them, running the test suite, seeing a new failure, and fixing that too. Long-horizon reliability — staying coherent and on-task across many steps without drifting — is one of the hardest problems in the field and one of the clearest ways frontier models separate themselves.
3. Reading and editing a real codebase
Answering a coding question in isolation is easy. Working inside a large, messy, real-world repository is hard. An agentic model has to navigate an unfamiliar project, respect its conventions, understand cross-file dependencies, and make surgical edits that do not break unrelated code. This is exactly what benchmarks like SWE-bench measure, and it is where the gap between a strong chat model and a strong agent is widest.
4. Self-correction
The defining behavior. When an agent runs a test and it fails, or a build breaks, it reads the error, forms a hypothesis, and tries again — the same way a human developer does. This closed feedback loop is what lets an agent recover from its own mistakes instead of confidently handing you broken code. A chatbot cannot self-correct because it never sees the consequences of its output; an agent lives inside those consequences.
5. Computer use
The newest frontier. Beyond the terminal, some models can now drive a graphical interface — moving a cursor, clicking buttons, filling forms, and reading the screen like a person would. This is called "computer use," and it lets an agent operate software that has no API: a legacy admin panel, a browser-based dashboard, a design tool. Computer-use agents extend the reach of coding models far beyond code itself.
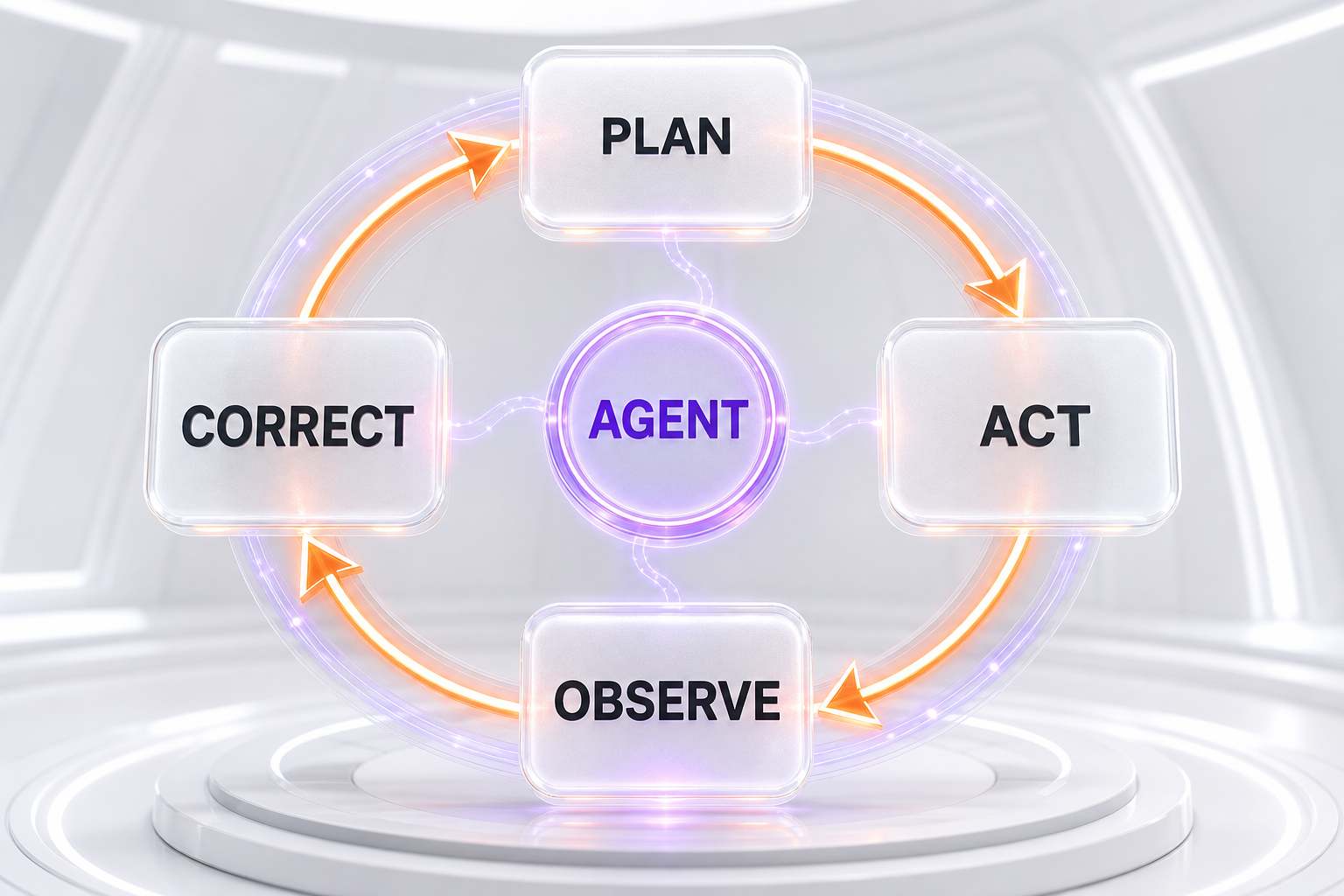
The Agentic Loop: Plan, Act, Observe, Correct
Everything an agentic coding model does can be reduced to one repeating cycle:
- Plan. The model breaks the goal into a sequence of steps and decides which action to take first.
- Act. It calls a tool — runs a command, edits a file, executes a test.
- Observe. It reads the tool's output: the test passed, the file was written, the command threw an error.
- Correct. Based on what it observed, it updates its plan and picks the next action. If something broke, it debugs.
The loop repeats until the task is complete or the model decides it needs human input. This is the entire trick. A chatbot does the "plan" step once and then stops. An agent runs the full loop, sometimes for an hour, and it is the "observe and correct" half that makes the output trustworthy. When people say a model is a good agent, they usually mean it stays productive deep into that loop instead of losing the thread after a few steps. This agentic loop has moved from a research demo to a daily developer tool.
The Capabilities and Benchmarks That Matter
Because "agentic" is a set of capabilities, you measure it with task-completion benchmarks, not trivia quizzes. Two families of benchmark matter most in 2026, and it is critical to understand what each one actually measures — and to never mix their scales.
Agentic coding: SWE-bench and SWE-bench Pro
SWE-bench is the reference benchmark for agentic software engineering. It gives a model a real GitHub issue from an open-source project and asks it to produce a patch that resolves the issue and passes the project's hidden tests. The model has to find the relevant code across many files, edit it correctly, and not break anything else. The full set contains 2,294 real issues; the widely cited SWE-bench Verified subset contains 500 tasks that human engineers confirmed are fair and solvable.
SWE-bench Pro is a deliberately harder, contamination-resistant evolution. It uses longer, multi-file tasks drawn from more commercial-style repositories, specifically designed so a model cannot have memorized the answer during training. Because Pro is harder by construction, scores on it are much lower than on Verified — and that is the point. A model's SWE-bench Pro number and its SWE-bench Verified number are not interchangeable. A lower Pro score does not mean a worse model; it means a harder test. Comparing a Verified score against a Pro score is a category error, and you will see it done constantly. Do not do it.
Computer use: OSWorld and OSWorld-Verified
OSWorld measures the other frontier — a model's ability to complete real tasks by driving a computer's graphical interface. It places the agent in a genuine operating-system environment with real applications (a browser, a file manager, office software) and scores whether it can accomplish 369 open-ended tasks such as "find this file and change a setting." OSWorld-Verified is a cleaned-up version with corrected task definitions and more reliable grading. These benchmarks test perception and GUI control, not code patches, so — once again — an OSWorld score has nothing to do with a SWE-bench score. They live on different axes and answer different questions.
The practical lesson: when someone quotes a benchmark to prove a model is "the best coder," ask which benchmark, on which scale, measuring which capability. If you want the full picture of how the leading tools stack up on the metrics that matter, our best AI coding tools of 2026 collection lays them side by side.
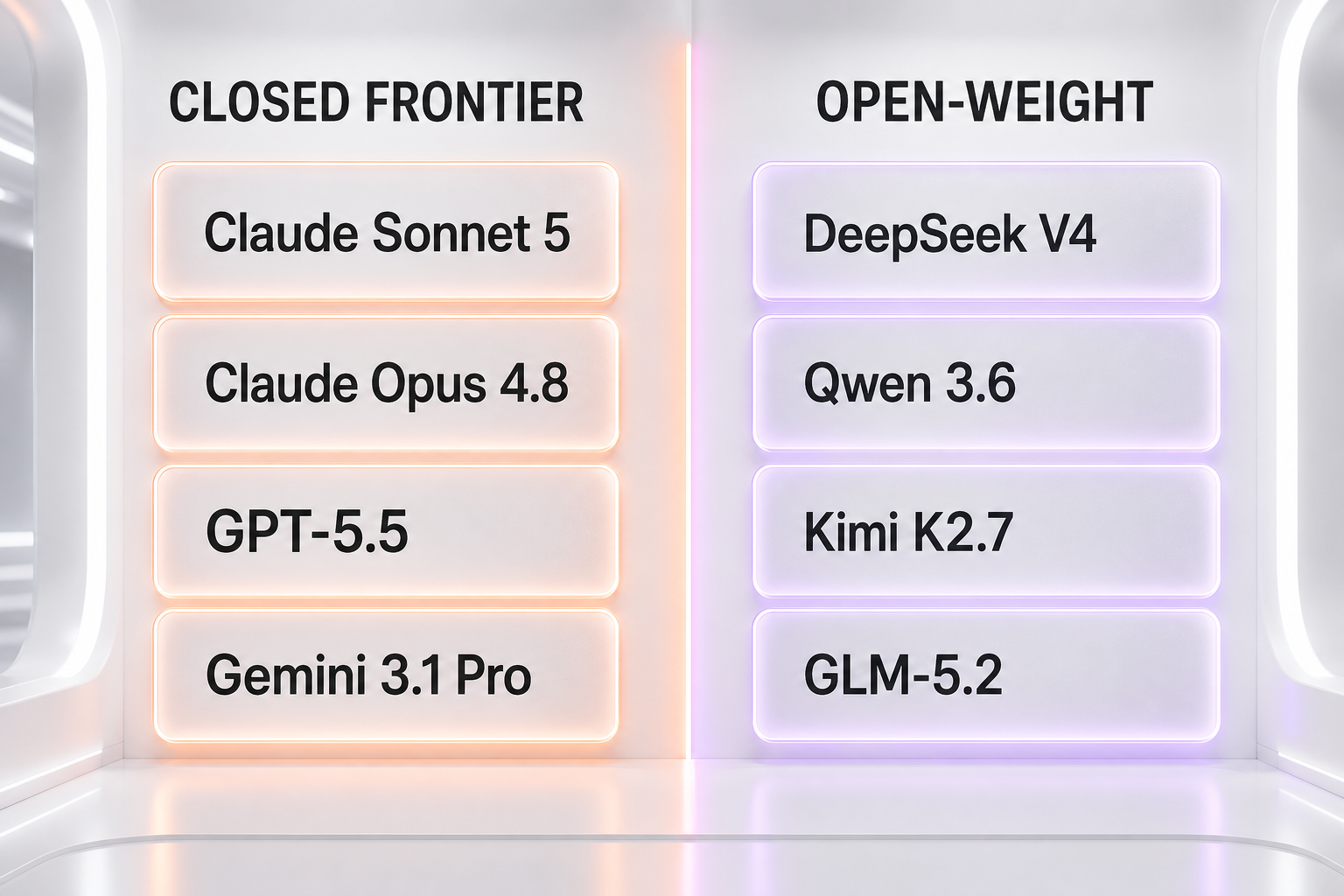
The 2026 Landscape: Closed and Open-Weight Agentic Models
Agentic coding ability now spans two camps: closed frontier models you access through an API, and open-weight models you can download and run yourself. Both are viable for serious agentic work, and the gap between them narrowed sharply through 2026.
Closed frontier models
These are the models most agents run on by default, tuned heavily for long-horizon tool use and reliability:
- Claude Sonnet 5 — Anthropic's workhorse, built to put near-flagship agentic coding into the affordable tier. It is the default engine behind a huge share of coding agents.
- Claude Opus 4.8 — the flagship for the hardest long-horizon tasks, where staying coherent across hundreds of steps matters most.
- GPT-5.5 — OpenAI's flagship, strong across reasoning, tool use, and computer use.
- Gemini 3.1 Pro — Google's reasoning-leaning frontier model with deep tool integration and a very large context window.
If you are choosing between them, our head-to-head comparisons are the fastest way to decide: Claude Sonnet 5 vs GPT-5.5 and Claude Sonnet 5 vs Gemini 3.1 Pro.
Open-weight challengers
The open-weight side matured fast, and for many teams the appeal is obvious: you can run the model on your own hardware, keep code private, and pay for compute instead of tokens.
- DeepSeek V4 — the price-to-performance benchmark of the open world, with strong agentic coding at a fraction of frontier cost.
- Qwen 3.6 — Alibaba's open family, widely used as a self-hosted coding agent backbone.
- Kimi K2.7 — Moonshot's open-weight model tuned for long-context, tool-heavy coding.
- GLM-5.2 — Zhipu's model, one of the strongest open performers on hard agentic coding tasks.
The open-weight race is close enough that it has its own comparisons worth reading — GLM-5.2 vs DeepSeek V4 and Kimi K2.7 vs DeepSeek V4 — and if you are weighing a closed model against an open one, Claude Sonnet 5 vs DeepSeek V4 frames the tradeoff directly.
Agentic Coding Tools You Can Use Today
A model is the engine; a coding tool is the car built around it. The agentic tools most developers reach for in 2026 wrap one of the models above in a terminal, file access, and a task loop:
- Claude Code — a command-line agent that reads and edits your whole repository, runs your tests, and works through multi-step tasks autonomously. If you are new to it, start with our beginner's guide, then level up with multi-agent teams and worktrees.
- Agent-first IDEs and CLI agents that run parallel fleets of agents across a codebase — compared head to head in Claude Code vs Cursor and Claude Code vs OpenAI Codex.
The tool determines the guardrails, the permissions, and how the loop is presented to you. But the ceiling on what any of them can do is still set by the agentic ability of the underlying model.
How Agentic Coding Changes the Way You Work
The shift from chatbot to agent is not a bigger autocomplete — it is a change in the unit of work. With a chatbot, you ask questions and stay in the driver's seat for every keystroke. With an agent, you delegate a task and move to a supervisory role: you describe the goal, the agent executes, and you review the result the way a senior engineer reviews a pull request.
In practice, three things change:
- From typing to reviewing. Your job shifts from writing every line to specifying intent clearly and verifying output. Prompting well and reviewing carefully become the core skills.
- From one task to many in parallel. Because an agent runs on its own, you can start several at once — one fixing tests, another writing docs, another prototyping a feature — and check in on each. This is why "multi-agent" workflows took off in 2026.
- From assistant to colleague. A chatbot is a reference you consult. An agent is closer to a junior teammate you assign work to — one that is fast and tireless but still needs clear direction and a code review before its work ships.
That last point is the honest one. An agent is a colleague you can delegate to, not a replacement you can forget about.
Limits and Open Problems
Agentic coding models are powerful, but the 2026 reality has hard edges worth naming:
- Long-horizon reliability. The longer a task runs, the more chances an agent has to drift, loop, or make a wrong turn it never recovers from. Frontier models are far better than a year ago, but they are not immune.
- Verification is your job. An agent that self-corrects against tests is only as safe as those tests. If the test suite is weak, the agent can confidently ship code that passes but is wrong. You still own the review.
- Cost and latency. A long trajectory can burn a lot of tokens and take real wall-clock time. For some tasks, running a frontier agent costs more than the engineering time it saves — a tradeoff worth measuring.
- Computer-use security. A model that can click buttons and fill forms is a model that can be manipulated by what it sees on screen. Prompt injection through a web page or a document is a genuine risk that the industry is still learning to contain.
None of these cancel the value. They just mean an agentic model is a capability to be managed, not a magic wand — which is exactly how any serious team treats it.
The Bottom Line
An agentic coding model is defined by what it can do, not what it can say. It plans, uses tools, drives a terminal or a screen, edits a real codebase across many steps, and corrects itself along the way. A chatbot answers a prompt; an autocomplete finishes a line; only an agent can be handed a goal and trusted to pursue it. That is the founding distinction of this era of software, and every model, tool, and benchmark we cover on ThePlanetTools.ai is best understood through it. Learn to tell the three modes apart, learn which benchmark measures which capability, and never mix the scales — and you will read the entire AI coding market clearly.
Frequently Asked Questions
What is an agentic coding model?
An agentic coding model is an AI system that plans a task, uses tools such as a terminal and file editor, edits a real codebase across many steps, and checks and corrects its own work until the goal is reached. Unlike a chatbot, which answers one prompt and stops, an agent can be handed a goal and will pursue it end to end.
How is an agentic coding model different from a chatbot?
A chatbot works in single turns: you send a prompt, it returns one answer, and it waits. An agentic model runs a loop — it plans, takes an action with a tool, observes the result, and corrects — repeating for many steps until a whole task is done. The chatbot describes what to do; the agent actually does it and verifies the outcome.
What is the difference between an AI agent and autocomplete like GitHub Copilot?
Autocomplete predicts the next line or block of code based on your cursor position — it operates in milliseconds and finishes what you are already typing. An agent is given a goal instead of a cursor position, and it works autonomously across minutes or hours: running commands, editing multiple files, and testing. Autocomplete assists your typing; an agent completes the task.
What makes a coding model "agentic"?
Five capabilities: tool use (calling a shell, editor, or test runner and reading the output), multi-step long-horizon execution, the ability to read and edit a real codebase, self-correction from errors, and increasingly computer use — driving a graphical interface directly. A model that cannot use tools cannot be agentic; it can only describe what a tool would do.
What is the agentic loop?
The agentic loop is the repeating cycle of plan, act, observe, and correct. The model breaks a goal into steps, takes an action with a tool, reads the result, updates its plan, and picks the next action — repeating until the task is complete. The "observe and correct" half is what makes an agent's output trustworthy, because it can recover from its own mistakes.
Which benchmarks measure agentic coding ability?
The main one is SWE-bench, which asks a model to resolve real GitHub issues by producing a patch that passes hidden tests. Its full set has 2,294 issues and the human-validated SWE-bench Verified subset has 500. Computer-use ability is measured separately by benchmarks like OSWorld. Trivia-style quizzes do not measure agentic ability; only task-completion benchmarks do.
What does SWE-bench Pro measure, and how is it different from SWE-bench Verified?
SWE-bench Pro is a deliberately harder, contamination-resistant version that uses longer, multi-file tasks from more commercial-style repositories, so a model cannot have memorized the answers. Scores on Pro are much lower than on Verified by design. The two numbers are not interchangeable: a lower Pro score means a harder test, not a worse model, and comparing a Verified score to a Pro score is a category error.
What is computer use in AI coding models?
Computer use is a model's ability to drive a graphical interface directly — moving a cursor, clicking buttons, filling forms, and reading the screen like a person. It lets an agent operate software that has no API, such as a legacy admin panel or a browser dashboard, extending coding agents far beyond the terminal and the code itself.
What is OSWorld-Verified?
OSWorld is a benchmark that measures computer use by placing an agent in a real operating-system environment with real applications and scoring whether it can complete 369 open-ended tasks. OSWorld-Verified is a cleaned-up version with corrected task definitions and more reliable grading. It tests GUI control and perception, not code patches, so an OSWorld score is unrelated to a SWE-bench score.
Which agentic coding models are available in 2026?
Closed frontier options include Claude Sonnet 5 and Claude Opus 4.8 from Anthropic, GPT-5.5 from OpenAI, and Gemini 3.1 Pro from Google. Open-weight options you can self-host include DeepSeek V4, Qwen 3.6, Kimi K2.7, and GLM-5.2. Both camps are viable for serious agentic work, and the gap between them narrowed sharply through 2026.
Are there open-weight agentic coding models?
Yes. DeepSeek V4, Qwen 3.6, Kimi K2.7, and GLM-5.2 are all open-weight models capable of serious agentic coding. Their appeal is that you can run them on your own hardware, keep code private, and pay for compute rather than per-token API fees. DeepSeek V4 in particular set the price-to-performance benchmark for the open-weight world.
Do agentic coding models replace developers?
Not in 2026. An agent is closer to a fast, tireless junior teammate you delegate tasks to than a replacement you can forget about. The developer's job shifts from writing every line to specifying intent clearly, running several agents in parallel, and reviewing their output the way a senior engineer reviews a pull request. Verification stays firmly a human responsibility.



