
Closed and open-weight AI models differ in one thing above all: who holds the weights. Closed, managed models such as Claude Sonnet 5, GPT-5.5, and Gemini 3.1 Pro are reached only through a vendor's hosted API, billed per token, with the model itself never leaving the vendor's servers. Open-weight models such as DeepSeek V4, Qwen 3.6, Kimi K2.7, and GLM-5.2 publish downloadable weights you can self-host, often under permissive licenses like MIT or Apache 2.0. The right choice is not about ideology; it comes down to five axes: cost, control and data residency, security and governance, ecosystem and support, and performance parity.
There is no universal winner. A cost-sensitive team running billions of tokens on non-sensitive data will reach a very different conclusion than a regulated bank that cannot let a single prompt leave its network — and both can be right. This article lays out the reference decision grid we use, defines the terms precisely, then walks through concrete usage profiles so you can map your own constraints to the correct model class.
The short answer
Choose a closed, managed model when you want the fastest path to production, the strongest frontier capability, and someone else to own the infrastructure and most of the governance. Choose an open-weight model when you need physical control over your data, predictable cost at high volume, version stability, or freedom from vendor lock-in — and you have, or can rent, the engineering capacity to run it. Most mature teams end up doing both: a closed frontier model for the hardest work, a cheaper open-weight model for the high-volume majority.
Decision grid at a glance
Read each axis as a lean, not an absolute. The point is to see which way your specific constraints push you.
| Decision axis | Leans closed / managed | Leans open-weight |
|---|---|---|
| Cost | Low or bursty volume; no wish to run infrastructure | High, steady volume where per-token savings and self-hosting pay off |
| Control & data residency | Vendor contractual guarantees are acceptable | Data must stay on-premises or in your own network; version pinning required |
| Security & governance | You want vendor-provided safety, compliance, and SLAs | You want full auditability and will own the guardrails yourself |
| Ecosystem & support | You need mature SDKs, integrations, and enterprise support now | You can assemble your own serving stack and accept community support |
| Performance parity | You need the frontier edge on the hardest tasks | Open-weight is already good enough for your everyday tasks |
The sections below unpack each row. If you only remember one thing: cost and control push you toward open weights; speed-to-production and frontier capability pull you back toward closed APIs.
What "closed" and "open-weight" actually mean
Closed and managed models
A closed, managed model — also called proprietary or API-only — runs entirely on the vendor's infrastructure. You send a request to a hosted endpoint and receive a response; the trained weights are never published. You pay per token, split between input and output, and the vendor handles scaling, uptime, safety filtering, and updates. The best-known families are Anthropic's Claude line, including Claude Sonnet 5 and Claude Opus 4.8, OpenAI's GPT-5.5, and Google's Gemini 3.1 Pro. The trade you are making is convenience and capability in exchange for data leaving your boundary and a model you do not physically control.
Open-weight models
An open-weight model publishes its trained weights for download. You, or a third-party inference provider acting on your behalf, can load those weights onto GPUs and run the model yourself. The most prominent open-weight families in 2026 come largely from Chinese labs — DeepSeek V4, Alibaba's Qwen 3.6, Moonshot's Kimi K2.7, and Zhipu's GLM-5.2 — alongside Western releases such as Meta's Llama 4, Mistral Large 3, and Google's Gemma 4. Many ship under permissive licenses like MIT or Apache 2.0. The trade here is control and cost flexibility in exchange for owning the infrastructure and the governance.
Open-weight is not the same as open-source
This distinction matters and is a frequent source of confusion. Open-weight means you get the finished weights. It does not guarantee you get the training data, the training code, or a fully unrestricted license. Open-source, in the strict sense used by the Open Source Initiative, implies a license with no field-of-use restrictions. In practice, some models labeled "open" carry acceptable-use clauses or scale-based conditions, and a few promise weights that arrive later than the announcement. The rule of thumb: treat "open-weight" as "downloadable and self-hostable," then read the actual license before you build a business on it, because terms genuinely vary by model and by version.

The five decision axes
Every real decision reduces to these five axes. Weight them by your own constraints — a startup optimizing for speed will rank them differently than a hospital optimizing for compliance.
Axis 1 — Cost
Cost is where the two models diverge most visibly. A closed API charges per token and nothing else: no servers, no GPUs, no on-call rotation. That is wonderful at low or unpredictable volume, and it scales linearly — which becomes the problem, because at very high volume a per-token bill on a frontier model grows without limit.
Open-weight gives you two cheaper paths. The first is renting the model from an inference provider that hosts the open weights and bills per token, typically at a fraction of frontier closed pricing. The second is self-hosting on your own or rented GPUs, where you pay for hardware or GPU rental billed per hour regardless of how many tokens you push through. Self-hosting has a high fixed cost and a real break-even point: it only wins when utilization is high and steady enough to amortize the hardware and the engineering time. Do not forget the hidden line items — MLOps, monitoring, autoscaling, and keeping the deployment patched are all real costs that a managed API absorbs for you.
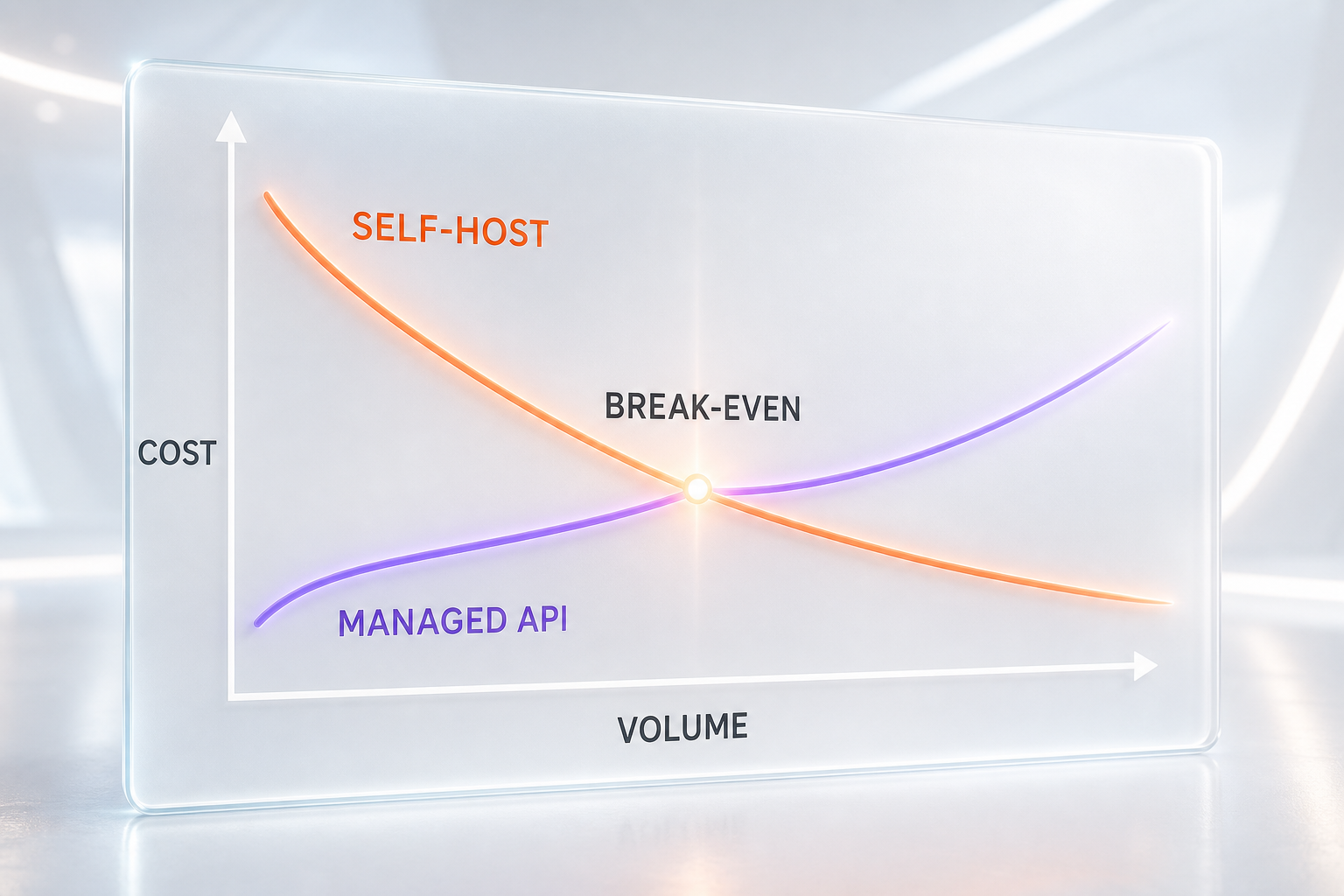
Axis 2 — Control, self-hosting, and data residency
This is the axis that most often forces the decision. With an open-weight model you can run inference entirely inside your own virtual private cloud or on-premises, which means prompts and outputs never cross your network boundary. For regulated industries — healthcare, finance, government, defense — and for organizations bound by data-residency rules such as keeping EU data in the EU, that physical isolation is frequently non-negotiable. Self-hosting also gives you version pinning: the model will not silently change or be deprecated underneath you, and you are free to fine-tune it on proprietary data. This local-control thesis is only getting stronger as hardware improves; we covered one facet of it in our analysis of the local-AI shift.
Closed vendors have responded with serious enterprise offerings: no-training-on-your-data commitments, zero-retention modes, regional endpoints, and audit logging. Those are meaningful, but they are contractual assurances, not physical guarantees — you are trusting a policy rather than a network diagram. If your threat model or your regulator does not accept that, open-weight self-hosting is the honest answer.
Axis 3 — Security, governance, and documentation
Closed vendors typically ship a mature governance package out of the box: content moderation, safety tooling, model cards, compliance certifications, and support with SLAs. That offloads a large amount of work and risk, which is why security-conscious teams without a dedicated ML platform group often start there.
Open-weight flips the responsibility to you. You inherit full auditability and no vendor policy lock-in, but you must add your own guardrails, red-teaming, monitoring, and abuse controls. It is worth being clear-eyed about one property of open weights: safety alignment baked into a released model can be removed by anyone who fine-tunes it, so the guardrails on an open-weight model behave more like a default setting than a locked door. That is a feature for legitimate customization and a risk you have to manage in production. Governance with open weights is not absent — it is simply yours to build.
Axis 4 — Ecosystem and support
Closed frontier vendors have a head start on the surrounding ecosystem: polished SDKs, reliable tool use and function calling, structured outputs, first-party agent tooling such as Claude Code, deep third-party integrations, thorough documentation, and paid enterprise support. If your priority is to ship next quarter, that maturity is a genuine advantage.
The open-weight ecosystem is catching up quickly. Serving stacks, quantization, low-rank fine-tuning, and broad provider coverage now make open weights far easier to deploy than they were a year ago, and hardware-efficient releases keep lowering the barrier — see, for example, Cohere's Command A running on two GPUs and NVIDIA's Nemotron 3 Ultra. But you still assemble more of the stack yourself, and support is largely community-driven rather than a phone number with a contract behind it.
Axis 5 — Performance parity
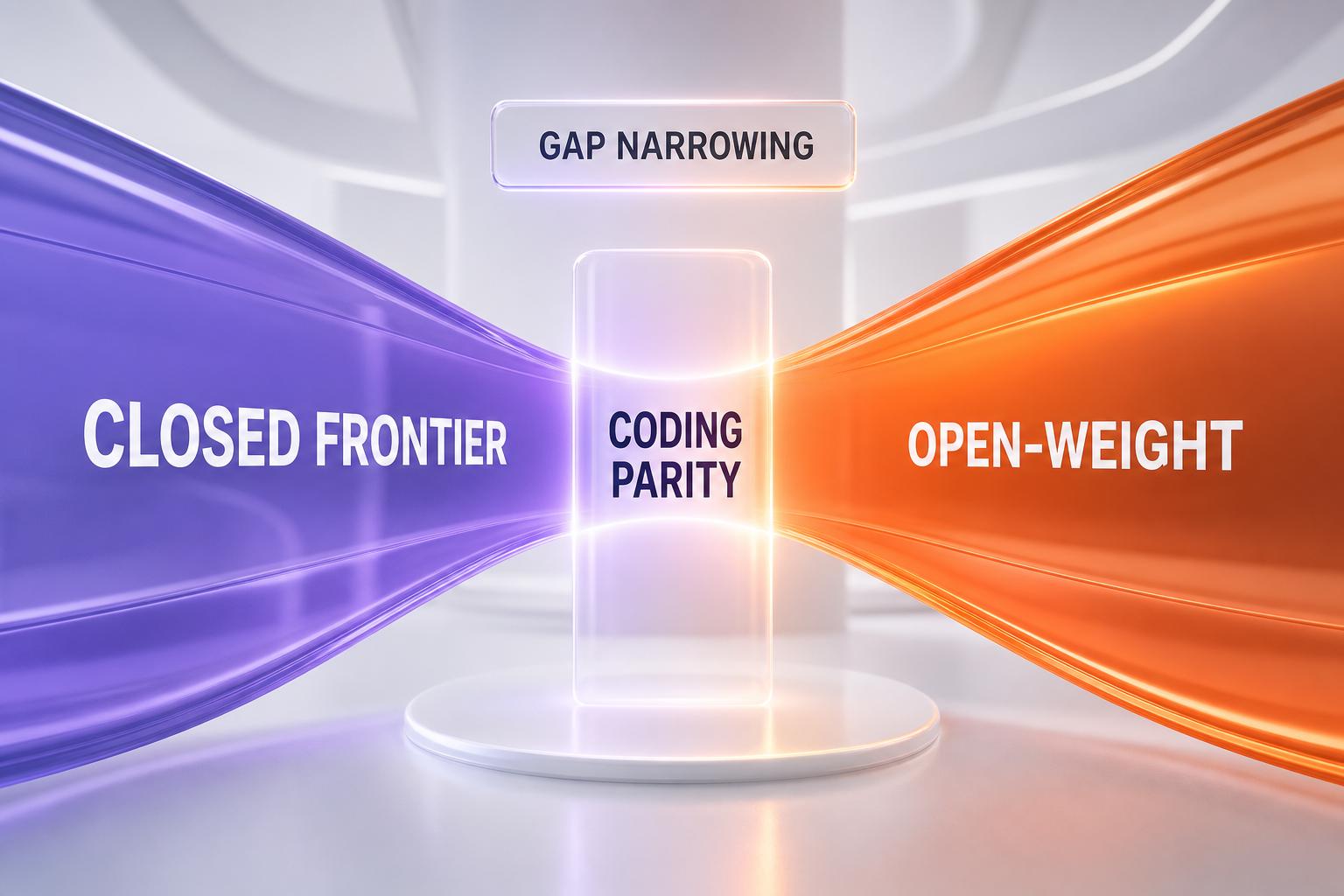
A few years ago the capability gap was the whole argument; today it is much narrower, and coding is where it has closed fastest. Top open-weight models are now broadly competitive with closed frontier models on many public coding and math tasks, which is precisely why open-weight adoption has accelerated among engineering teams. The launch of DeepSeek V4 and the wave of Chinese open-weight coding models — compared directly in our look at GLM-5.2 versus Kimi K2.7-Code — made that parity hard to ignore.
Closed frontier models still hold an edge where it is hardest to close: long-horizon agentic tasks, the most demanding reasoning, the broadest multimodal capability, and being first to new features. So the honest read is not "open weights have won" but "open weights are good enough for a growing majority of tasks, while the frontier premium is real for a shrinking, high-value minority." For the exact shape of that gap on any given pair, our head-to-head comparisons are the fastest way to check: Claude Sonnet 5 vs DeepSeek V4, Claude Sonnet 5 vs Qwen 3.6, Claude Sonnet 5 vs Kimi K2.7, Claude Sonnet 5 vs Kimi K2.6, and Claude Sonnet 5 vs GLM-5.2.
When to choose which — concrete usage profiles
Axes are abstract; decisions are not. Here is how the grid resolves for the profiles we see most often.
The cost-sensitive team at scale
If you run high, steady volume on non-sensitive data — think classification, summarization, or code generation across millions of requests — the per-token bill on a frontier closed model becomes the dominant line item. This is the clearest case for open-weight, either rented from a cheap inference provider or self-hosted once utilization justifies the fixed cost. Models like DeepSeek V4, Qwen 3.6, and GLM-5.2 are built for exactly this economics.
Sensitive data, on-premises, or regulated
If a single prompt leaving your network is unacceptable — patient records, financial data, classified material, or a strict data-residency mandate — self-hosted open-weight is usually the only option that fully satisfies the requirement. You trade convenience for physical control, and for these workloads that trade is the entire point. Kimi K2.7 and other open-weight models can be deployed inside an air-gapped environment where no managed API is permitted.
You need a mature ecosystem and want to ship fast
If you are a small team without an ML platform group, or you simply need to be in production quickly with agentic tooling and strong reasoning, a closed, managed model is the pragmatic default. Claude Sonnet 5, GPT-5.5, and Gemini 3.1 Pro get you a polished SDK, dependable tool use, and vendor governance on day one. The premium buys you speed and offloaded risk.
Rapid prototyping and experimentation
When you are still figuring out whether the product works at all, infrastructure is a distraction. Start on a managed API to validate the idea with zero setup, then revisit the model choice once you understand your real volume and data-sensitivity. Premature self-hosting is a common way to burn weeks on MLOps for a feature that has not proven itself.
Most real teams: the hybrid router
In practice, the mature answer is rarely all-or-nothing. Many teams route the hardest fraction of requests — the complex, agentic, high-stakes 20% — to a closed frontier model, while serving the high-volume, lower-complexity 80% on a cheaper open-weight model. That hybrid captures most of the cost savings without giving up the frontier where it matters, and it keeps you portable if pricing or parity shifts. Building a router is more work than picking one model, but for anything at scale it is usually the design that wins.
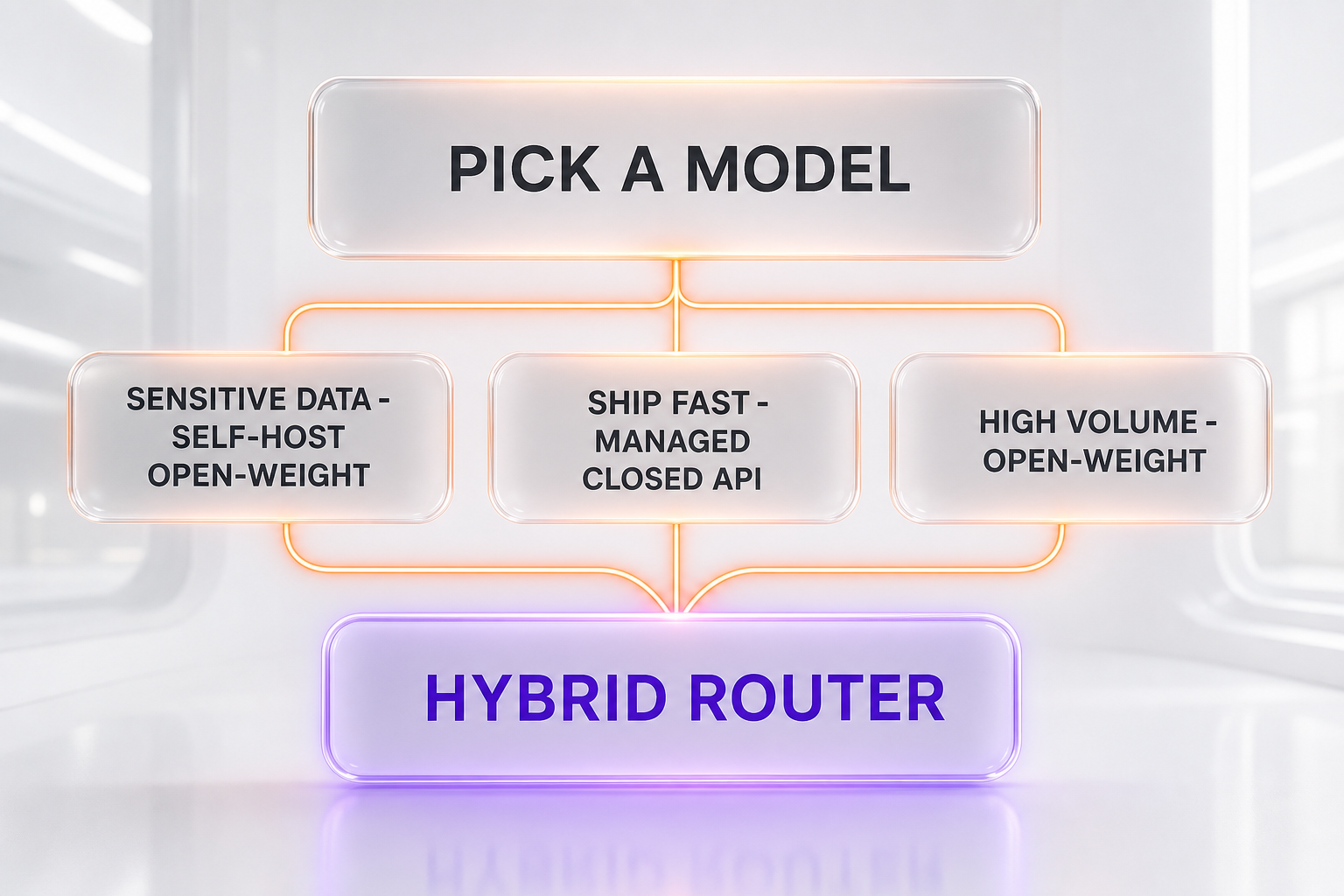
The real trade-off
Strip away the tribalism and the decision is operational, not moral. Open weights genuinely win on three things: cost at scale, physical control over data, and freedom from lock-in. Closed, managed models genuinely win on three others: time to production, frontier capability on the hardest tasks, and offloaded governance and support. Nobody wins on all six, which is why "open is always better" and "closed is always better" are both wrong.
The variable that decides your answer is your constraints, in this order: how sensitive is your data, how high and steady is your volume, and how much ML platform capacity do you have in house. If your data is sensitive or your volume is enormous and steady, open weights pull hard. If you need to ship fast, want the frontier, and lack an MLOps team, closed pulls hard. If you are somewhere in the middle — which is most teams — the hybrid router is the honest default.
One more thing that keeps this from being a one-time decision: parity keeps moving. Open-weight models are improving faster than closed models are getting cheaper, so the break-even keeps shifting toward open weights for more task types each cycle. Whatever you choose, design so you can switch — abstract your model calls, keep prompts portable, and re-run this grid every few months rather than treating today's answer as permanent.
A quick decision checklist
When you are unsure, answer these in order and stop at the first firm "yes":
- Must your data stay inside your own network? If yes, self-hosted open-weight is likely your only fully compliant option.
- Is your volume high, steady, and non-sensitive? If yes, open-weight (rented or self-hosted) usually wins on cost.
- Do you need to ship in weeks with no ML platform team? If yes, start on a closed, managed API.
- Do you need the frontier edge on the hardest agentic or reasoning tasks? If yes, keep a closed frontier model in the mix.
- Is it a mix of the above? If yes, build a hybrid router and route by task.
For the coding case specifically, our roundup of the best AI coding tools in 2026 weighs closed and open-weight options side by side, so you can see how this grid resolves in one concrete domain.
Frequently asked questions
What is the difference between closed and open-weight AI models?
Closed, managed models like Claude Sonnet 5, GPT-5.5, and Gemini are accessed only through a vendor's hosted API and billed per token; the weights are never released. Open-weight models like DeepSeek V4, Qwen 3.6, Kimi K2.7, and GLM-5.2 publish their trained weights for download, so you can run them on your own hardware. The practical difference is who controls the infrastructure, the data path, and the cost structure.
Is open-weight the same as open-source?
No. Open-weight means the trained model weights are downloadable, but the training data and full training code are usually not released, and the license may add use restrictions. Open-source in the strict sense means an OSI-approved license with no such limits. Many popular models are open-weight under permissive licenses like MIT or Apache 2.0, but you should always read the specific license, because terms vary by model and version.
Are open-weight models like DeepSeek and Qwen as good as Claude and GPT?
On many everyday coding, math, and text tasks the gap has narrowed to the point where top open-weight models are competitive with closed frontier models. Closed frontier models still tend to lead on the hardest agentic, long-horizon, and multimodal tasks and usually ship new capabilities first. For a task-by-task view, see our head-to-head comparisons such as Claude Sonnet 5 vs DeepSeek V4 and Claude Sonnet 5 vs Qwen 3.6.
Is it cheaper to self-host an open-weight model or use a closed API?
It depends on volume and utilization. Self-hosting carries high fixed costs — GPUs or GPU rental billed per hour, plus engineering and operations time — that only pay off at high, steady usage. For low or bursty workloads, a managed API is usually cheaper all-in because you pay only per token and run no infrastructure. Renting an open-weight model from an inference provider sits between the two: per-token billing, typically far below frontier closed pricing.
Which type is better for sensitive or regulated data?
Open-weight models are often the stronger choice when data cannot leave your environment, because you can run them entirely inside your own network or on-premises, giving you physical control and data residency. Closed vendors offer enterprise terms such as no-training guarantees, zero-retention modes, and regional endpoints, but those are contractual assurances rather than physical isolation. Workloads that require air-gapped deployment usually lean open-weight.
Do I need my own GPUs to use open-weight models?
No. You can run open-weight models like DeepSeek V4 or GLM-5.2 through third-party inference providers that host them and bill per token, with no hardware to manage. You only need your own GPUs when you require full data isolation, custom fine-tuning, or predictable cost at very high volume.
What license do open-weight models use?
Many use permissive licenses such as MIT or Apache 2.0, which allow commercial use and self-hosting. However, some so-called open licenses add acceptable-use clauses or scale-based restrictions, so the terms are not identical across models. Always check the exact license for the specific model and version you plan to deploy.
When should I choose a closed model like Claude Sonnet 5 or Gemini?
Choose a closed, managed model when you want the fastest path to production, the strongest frontier capability, mature tooling and integrations, and vendor-provided governance, safety, and support. It is the right default for rapid prototyping, small teams without in-house MLOps, and workloads that need the hardest reasoning or the newest features first.
When should I choose an open-weight model like Kimi K2.7 or GLM-5.2?
Choose an open-weight model when you need physical control over your data, predictable cost at high and steady volume, version stability so the model cannot change under you, freedom to fine-tune, or independence from a single vendor. It fits regulated, on-premises, and cost-sensitive workloads, provided you have the engineering capacity to run and monitor it.
Can I mix closed and open-weight models in one product?
Yes, and most mature teams do. A common pattern is a router that sends the hardest fraction of requests to a closed frontier model while handling the high-volume, lower-complexity majority on a cheaper open-weight model. This hybrid approach balances capability, cost, and control, and lets you reassess as parity shifts.
Does closed vs open-weight matter for AI coding tools?
Yes. Coding is where open-weight models have closed the gap fastest, so many teams now run cost-effective open-weight models for routine code generation while reserving a closed frontier model for complex, agentic work. Our roundup of the best AI coding tools in 2026 covers both closed and open-weight options side by side.



